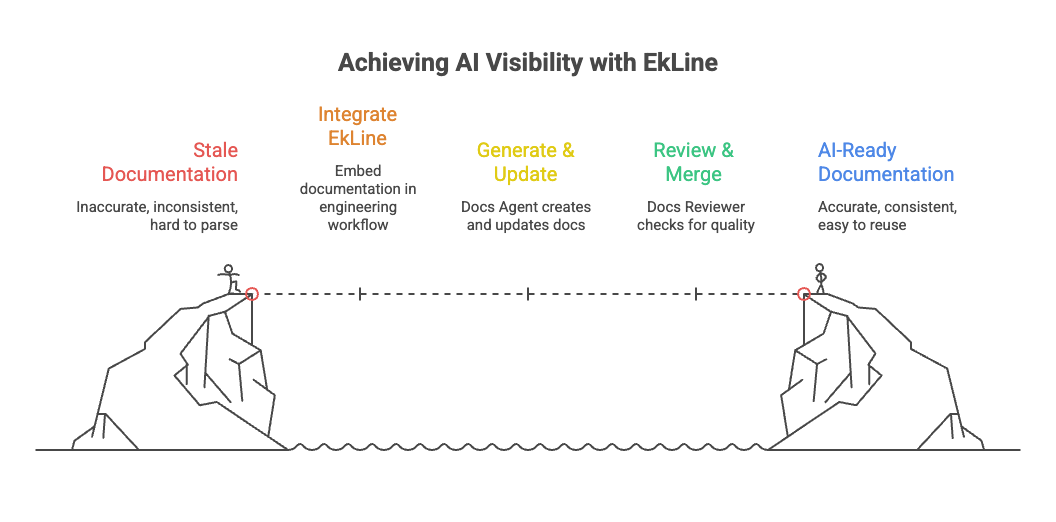
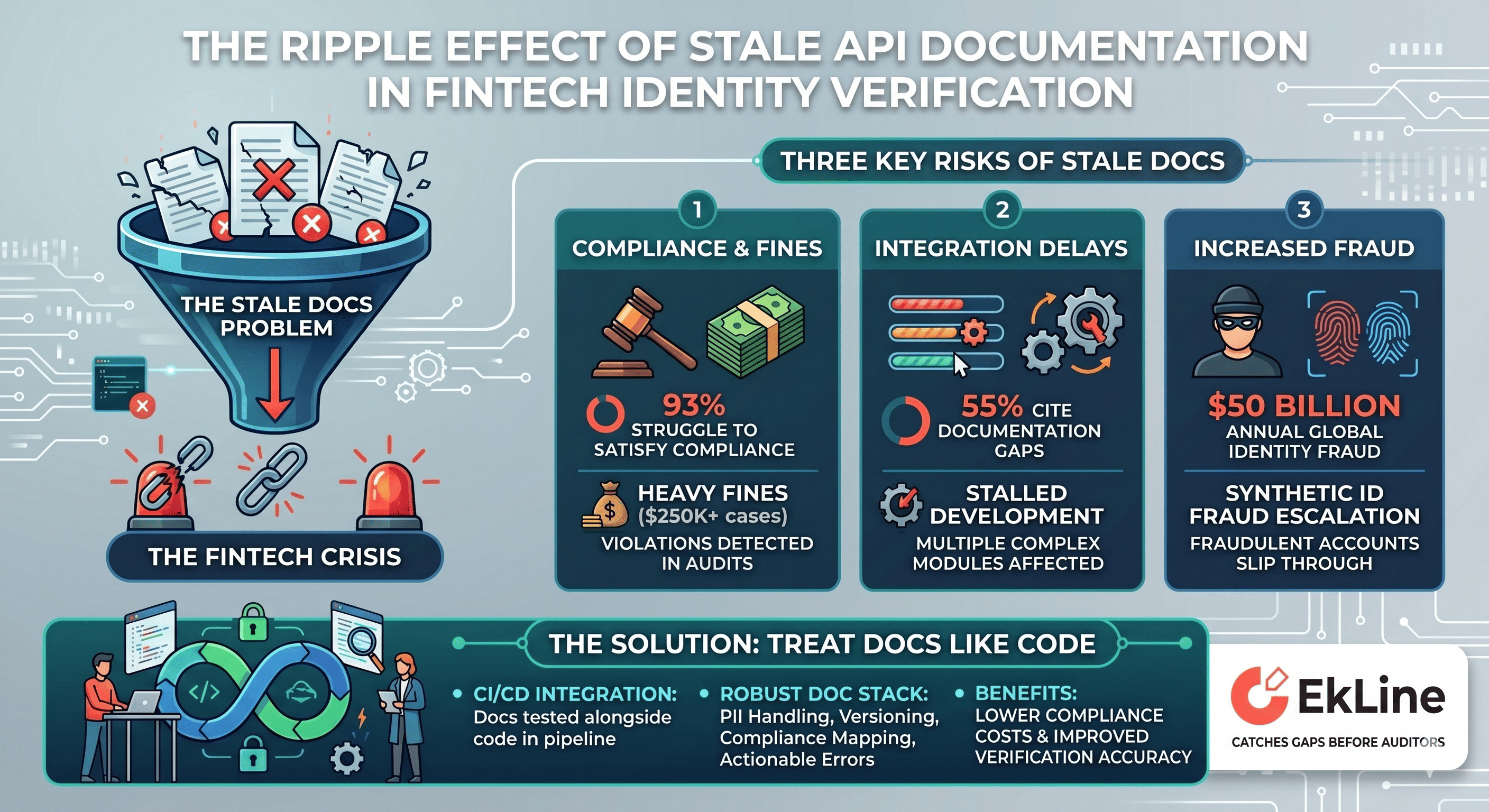
BlogYour Knowledge Base Is Your Next Growth Channel
With 58% of Google searches now ending without a click and AI answer engines (like ChatGPT and Google AI Overviews) handling billions of queries, traditional SEO is losing ground.
Fifty-eight percent of Google searches now end without a click. ChatGPT handles over 2 billion queries daily. Google AI Overviews appear in nearly 55% of all searches. If your product documentation lives behind a login or sits in a PDF that no crawler can reach, you are invisible to the systems that are now answering your customers' questions.
This is not a future problem. It is a Q1 2026 problem. And the fix is not more blog posts. It is making your knowledge base public, structured, and optimized for the engines that are replacing the search bar.
The Shift from Search Engines to Answer Engines
Traditional SEO optimized for page-level ranking: title tags, backlinks, keyword density. Answer Engine Optimization (AEO) operates at the fact level. AI systems extract individual claims, definitions, and data points from your content and present them as direct answers.
Here is the difference that matters: 60% of sources cited by AI are not in Google's top 10 results. A page that ranks #47 in traditional search can still be the source ChatGPT or Perplexity cites when a user asks "how does identity verification work with webhooks?"
This changes what content is valuable. Your blog posts compete with millions of other blog posts. Your public knowledge base, the one that explains exactly how your product works, has a structural advantage: it contains authoritative, specific, product-level information that no competitor blog can replicate.
Why Knowledge Bases Outperform Blog Content for AEO
A blog post says "webhook retries are important for reliability." Your knowledge base says "our webhook retry policy sends 3 attempts at 30-second intervals, returns a 410 if the endpoint is deregistered, and logs all attempts to the audit trail accessible at /settings/webhooks/logs."
AI answer engines prefer the second version. It is specific. It is verifiable. It is the kind of content that gets cited because it directly answers a technical question with no ambiguity.
The data backs this up:
- AI-driven visitors convert at 4.4x the rate of standard organic visitors
- AI visitors spend 68% more time on site than traditional search visitors
- AI referral traffic grew 527% year-over-year through mid-2025
- One documentation platform reported a 5x increase in web traffic after optimizing their public knowledge base for search
When your knowledge base ranks in an AI citation, the person reading that answer is not browsing. They are solving a specific problem. They already have intent. That is why the conversion rate is 4.4x higher.
What "Public" Actually Means
Making your knowledge base public does not mean dumping your internal wiki onto a subdomain. It means treating your documentation as a product surface that is:
Crawlable. Every page has a clean URL, proper heading hierarchy (H1, H2, H3), and meta descriptions under 155 characters. No JavaScript-rendered content that bots cannot parse.
Structured for extraction. AI systems pull the first 40-60 words of a section to determine if it answers a query. Lead each section with a direct answer, not context-setting preamble. Use FAQ schema, Article schema, and BreadcrumbList schema so AI systems can understand the content hierarchy.
Fresh. AI-surfaced URLs are 25.7% fresher than traditional search results. AI citations decay after approximately 13 weeks without updates. If your knowledge base articles have not been updated since the last product release, they are losing citation eligibility every week.
Authoritative. Include citations every 150-200 words. Link to your own API reference, changelogs, and status pages. External links to standards bodies (NIST, OWASP, FHIR) and industry reports reinforce trust signals that AI systems use to determine citation quality.
The CTA That Writes Itself
Most tech companies already have a knowledge base. Some version of it exists in Zendesk, Confluence, Notion, or a docs-as-code repo. The problem is not creating content. The problem is that the content is either private, unstructured, or stale.
Here is the gap: 70% of organizations believe AEO will significantly impact their digital strategy within 1-3 years, but only 20% have started implementing it. That 50-point gap is the window.
The companies that move their knowledge base from "internal support tool" to "public product surface optimized for AI citation" will show up in the answers their competitors' customers are asking. The ones that wait will wonder why their paid search costs keep climbing while organic discovery flatlines.
The Move: From API Docs to Public Knowledge Base
API docs are necessary. They serve the developer who has already decided to integrate. But they do not serve the developer who is evaluating whether to integrate, the product manager researching solutions, or the AI system trying to answer "what is the best way to verify identity with webhooks?"
A public knowledge base covers the full surface:
- Concepts that explain why your product exists and what problems it solves (AEO-optimized for discovery queries)
- Guides that walk through implementation step by step (AEO-optimized for how-to queries)
- Reference that documents every endpoint, parameter, and error code (AEO-optimized for specific technical queries)
- Troubleshooting that addresses the exact questions your support team answers every week (AEO-optimized for problem queries)
The troubleshooting layer is the most undervalued. Every support ticket your team resolves contains a question that someone else is asking ChatGPT right now. If your public knowledge base answers it with specificity and authority, your product gets cited. If it does not, a competitor's blog or a random Stack Overflow thread gets cited instead.
What This Looks Like in Practice
# Knowledge base structure optimized for AEO
knowledge-base/
concepts/
what-is-identity-verification.md # Discovery queries
how-kyc-compliance-works.md # Evaluation queries
guides/
quickstart-identity-check.md # Implementation queries
webhook-retry-configuration.md # Configuration queries
reference/
api-endpoints.md # Technical queries
error-codes.md # Debugging queries
troubleshooting/
common-integration-errors.md # Problem queries (from support tickets)
webhook-delivery-failures.md # Problem queries (from support tickets)
Each page follows the answer-first pattern: direct answer in the first 40-60 words, supporting detail below, schema markup for AI extraction.
Start Here
If your knowledge base is behind a login, make one section public this week: your troubleshooting articles. They map directly to the questions AI systems are already answering about your product category. Structure them with clear question-and-answer formatting, add FAQ schema, and make sure each article leads with a direct, specific answer.
That single move puts you in the 20% of companies that have started optimizing for answer engines while the other 80% are still debating it.
If your knowledge base is already public but has not been updated since your last release, EkLine flags the drift before your AI citation window closes.